SQL loader - Comment charger des données rapidement?
SQL Loader est un outil Oracle vraiment robuste pensé pour charger très rapidement de gros volumes de données dans une base Oracle. Plutôt que d'importer chaque enregistrement à la main, SQL Loader fait le travail grâce à des fichiers de contrôle et de données bien conçus. Cela donne un coup de fouet au processus d'intégration. C’est surtout un as quand les données viennent de systèmes externes ou qu’on doit gérer une migration de grande ampleur.
Introduction à SQL Loader et à ses principaux composants, où l'on va démêler tout ça avec un brin de clarté et un soupçon de bonne humeur
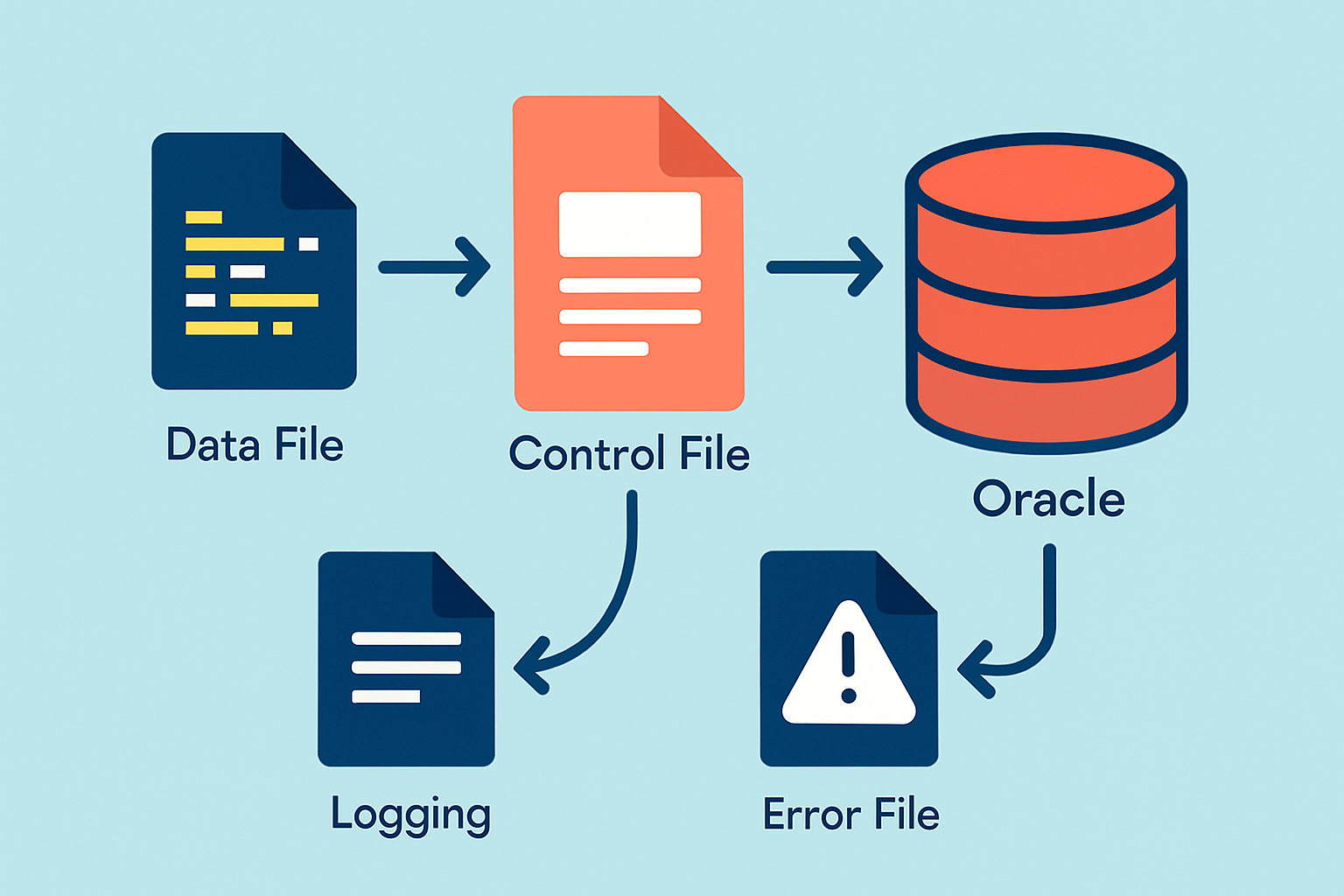
SQL Loader fonctionne en jonglant habilement avec plusieurs fichiers. Les données à charger sont généralement sous un format texte simple comme bonjour. Il y a aussi le fameux fichier de contrôle qui décrit méticuleusement la structure et la transformation de ces données. Sans oublier les fichiers de journalisation, qui jouent un peu les reporters en détaillant chaque étape du processus et les erreurs potentielles survenues en chemin.
- Le fichier de contrôle (.ctl) décrit la structure des données, les règles de chargement et les instructions SQL. C'est la feuille de route qui guide tout le processus.
- Le fichier de données contient les enregistrements bruts à importer, généralement au format texte simple, essentiel pour le processus.
- Le fichier log garde une trace de toutes les étapes et erreurs du processus. C'est notre journal intime de chargement.
- Le fichier bad regroupe les données rejetées qui n'ont pas passé le test à cause d’erreurs de format ou de contraintes. C'est le coin où l'on met les dossiers qui ont fait des siennes.
- Le fichier discard stocke les enregistrements ignorés selon les critères définis dans le fichier de contrôle. Cela permet de garder notre jeu de données propre et net.
Optimiser vos fichiers pour un chargement efficace avec SQL Loader, sans prise de tête
Une préparation aux petits oignons des fichiers de données et de contrôle est absolument cruciale pour booster à la fois la rapidité et la fiabilité du chargement. Il ne suffit pas de faire au plus simple. Il faut choisir un format de données limpide comme de l'eau de roche, définir avec précision les champs dans le fichier de contrôle et surtout bien maîtriser les options qui jonglent avec encodages et séparateurs.
- Choisissez un format de fichier qui colle bien à vos besoins : le CSV est la valeur sûre et simple à manier tandis que le format à largeur fixe fait des merveilles quand les données sont plus structurées.
- Pensez à bien préciser chaque champ avec son type dans votre fichier de contrôle. C’est la clé pour un parsing qui ne vous joue pas de tours.
- Faites gaffe aux séparateurs et délimiteurs car ce sont souvent eux les petits coquins responsables des galères de lecture.
- Vérifiez et standardisez les encodages. J’ai toujours tendance à recommander UTF-8 car c’est la langue universelle qui évite bien des soucis d’interprétation des caractères.
Guide pratique pour charger vos données avec SQL Loader, sans prise de tête
Installez Oracle Client ou Oracle Database qui inclut le fameux SQL Loader. Ensuite, pensez à bien configurer vos variables d'environnement pour que l'outil veuille bien coopérer.
Écrivez un fichier de contrôle (.ctl) qui décrit la structure de vos données, les tables cibles et bien sûr les règles du jeu pour le chargement.
Préparez votre fichier de données en suivant scrupuleusement la structure définie. Prenez soin de nettoyer les données et veillez à ce que les formats soient cohérents.
Lancez la commande sqlldr avec les options nécessaires, par exemple : sqlldr userid=scott/tiger control=monfichier.ctl log=monfichier.log.
Une fois l’exécution terminée, jetez un œil attentif aux fichiers log et bad pour vous assurer que tout s’est bien passé. N’hésitez pas à corriger les petites erreurs qui auront pu surgir.
Quand vos données sont enfin chargées et validées, libre à vous d’exécuter des requêtes ou traitements sur votre base Oracle pour tirer pleinement parti de vos données importées.
Booster les performances de SQL Loader astuces et options avancées à ne pas manquer
Pour tirer vraiment le meilleur parti de SQL Loader, il faut bien maîtriser quelques options avancées qui peuvent booster la vitesse et l’efficacité du chargement. On pense notamment au mode de chargement direct, à l’utilisation du parallélisme et au réglage fin du nombre de lignes par transaction sans oublier une gestion très précise des erreurs.
- Utilisez
DIRECT=TRUEpour bénéficier d'un chargement direct qui saute quelques étapes SQL, ce qui peut vraiment donner un coup de fouet au processus. - Activez
PARALLELpour jouer la carte du multitâche en traitant plusieurs fichiers à la fois, histoire de tirer pleinement parti du multi-threading du serveur. - Ajustez la valeur
ROWSpour dénicher ce juste milieu entre la taille des lots envoyés à la base, la rapidité et la mémoire consommée. - Employez
SKIPpour zapper un certain nombre d'enregistrements pendant le chargement, super pratique quand il faut reprendre là où on s’était arrêté sans tout recommencer. - Gérez les erreurs avec
ERRORSen fixant combien d’erreurs on tolère avant de tirer la prise sur le processus. - Pensez aux tables externes (
EXTERNAL TABLES) pour charger vos données tout en profitant des fonctionnalités SQL, un peu comme avoir le beurre et l'argent du beurre. - Choisissez entre
TRUNCATEouAPPENDselon que vous préférez vider la table avant de charger ou simplement y ajouter les nouvelles données, selon le scénario du moment. - Contrôlez les transactions avec
CONSISTENTetUNRECOVERABLEpour jongler au mieux entre sécurité et performance.
Gestion des erreurs et dépannage courant avec SQL Loader astuces et solutions au quotidien
Quand on charge des données, il n’est pas rare de tomber sur des erreurs qui jouent les trouble-fête souvent liées au format ou à la structure. Heureusement, SQL Loader est là pour nous filer un coup de main en mettant en lumière ces anomalies grâce aux fichiers bad et discard. Savoir déceler ces pépins et remonter vite à la source du problème dans les fichiers de contrôle ou les données.
- Erreurs liées à un format de données incorrect dans le fichier source comme des délimiteurs qui jouent à cache-cache ou qui se retrouvent complètement à côté de la plaque.
- Violations des contraintes en base par exemple des clés primaires en double qui font lever les sourcils ou des règles d’intégrité qui sont gentiment bousculées.
- Soucis d’encodage qui transforment les caractères en hiéroglyphes incompréhensibles ou pire qui font purement et simplement rejeter la donnée.
- Erreurs dans le fichier de contrôle notamment des fautes de syntaxe dignes d’un cours débutant ou un alignement des colonnes qui fait un peu figure de foire aux bestiaux.
- Gestion des rejets grâce à la configuration des seuils d’erreur, une petite astuce bien pratique pour éviter que tout le chargement ne parte en fumée d’un coup.
Cas pratiques quelques exemples concrets de fichiers de contrôle et commandes SQL Loader qui tournent comme une horloge
Pour comprendre comment ça se passe sur le terrain, voici plusieurs exemples de fichiers de contrôle chacun taillé sur mesure pour différents scénarios. On trouve par exemple un fichier de contrôle simple pour un chargement CSV et un autre bien pensé pour les fichiers à format fixe sans oublier un fichier qui mise sur le chargement direct. Ces exemples ne s’arrêtent pas là. Ils intègrent aussi des options d’optimisation comme DIRECT=TRUE ou une gestion d’erreurs personnalisée pour éviter de mauvaises surprises. Vous allez aussi découvrir comment ajuster les commandes SQL Loader selon les particularités des jeux de données, ce qui rend leur intégration dans votre base Oracle rapide et rassurante.
| Type de fichier de données | Syntaxe principale utilisée dans le fichier de contrôle | Options d'optimisation employées | Performance observée |
|---|---|---|---|
| CSV simple | FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' | DIRECT=FALSE, APPEND | Chargement rapide, parfait pour les petits volumes où la patience n'est pas de mise |
| Format fixe | POSITION(x:y) avec types de données explicitement déclarés | DIRECT=TRUE, TRUNCATE | Très rapide, un vrai sprinter qui adore les données bien carrées |
| CSV chargé en parallèle | Plusieurs fichiers traités avec PARALLEL=TRUE | DIRECT=TRUE, ROWS=50000 | Optimisé pour avaler les très gros volumes sans broncher |
| Table externe | Usage d'EXTERNAL TABLES pour gérer les CSV | Pas de chargement direct, interrogation via SQL | Réduit les entrées/sorties, offrant une flexibilité bienvenue dans bien des cas |
| Chargement avec gestion d'erreurs | Utilisation de ERRORS=100 et BADFILE | Résilience face aux données parfois capricieuses | Chargement robuste et tolérant, parce que personne n'est parfait |